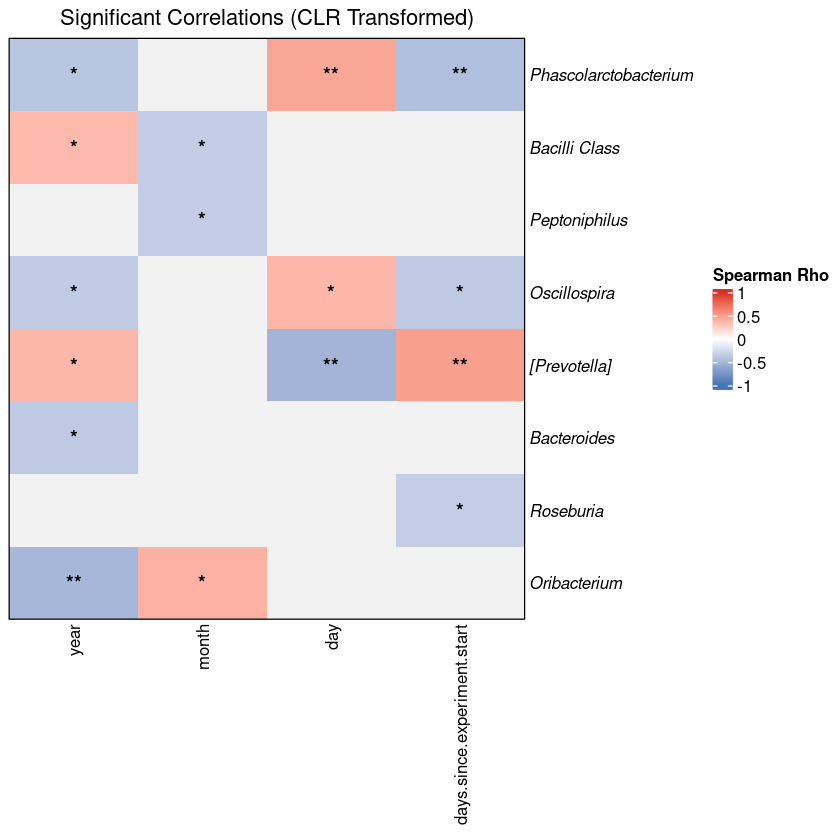
R Script · Downstream 16S Analysis · From OTUs to Figures in minutes
16S Structured R Workflow and Complete 16S Pipeline for Microbiome Analysis
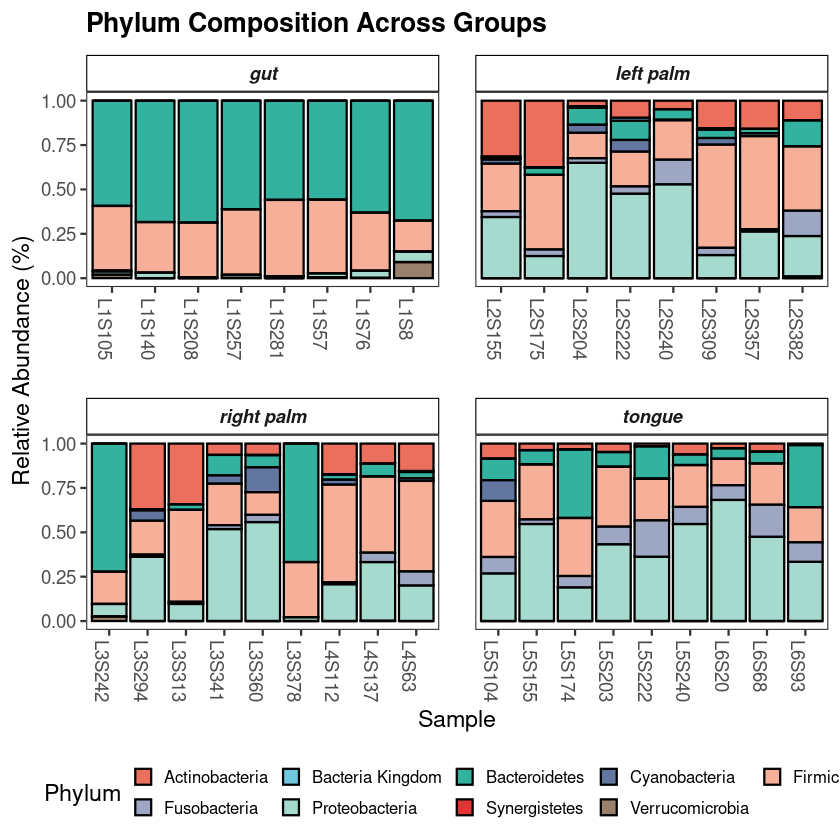
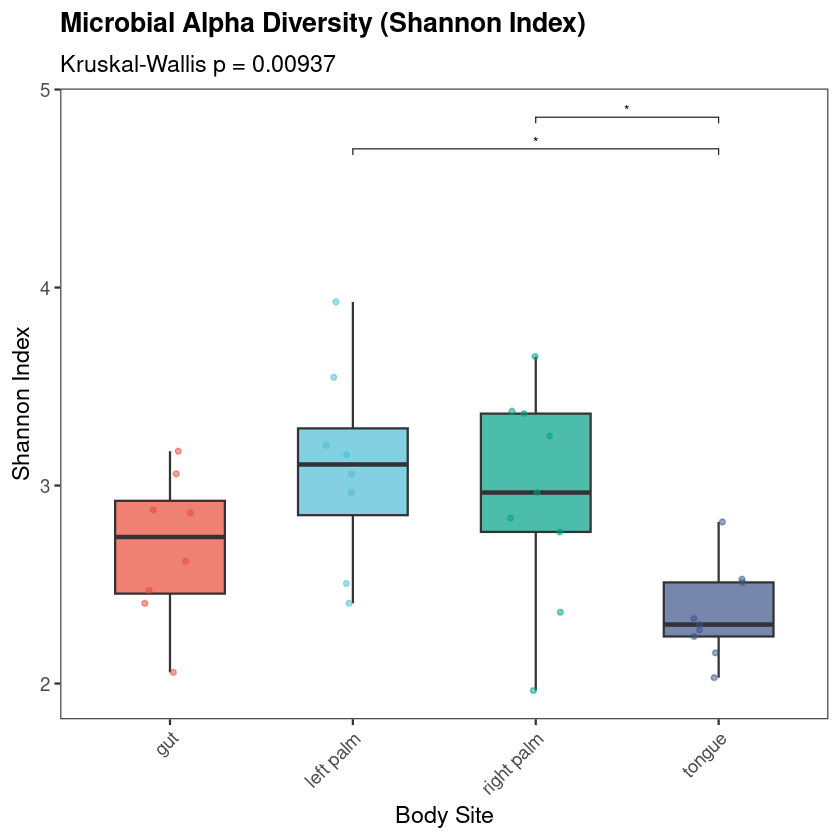
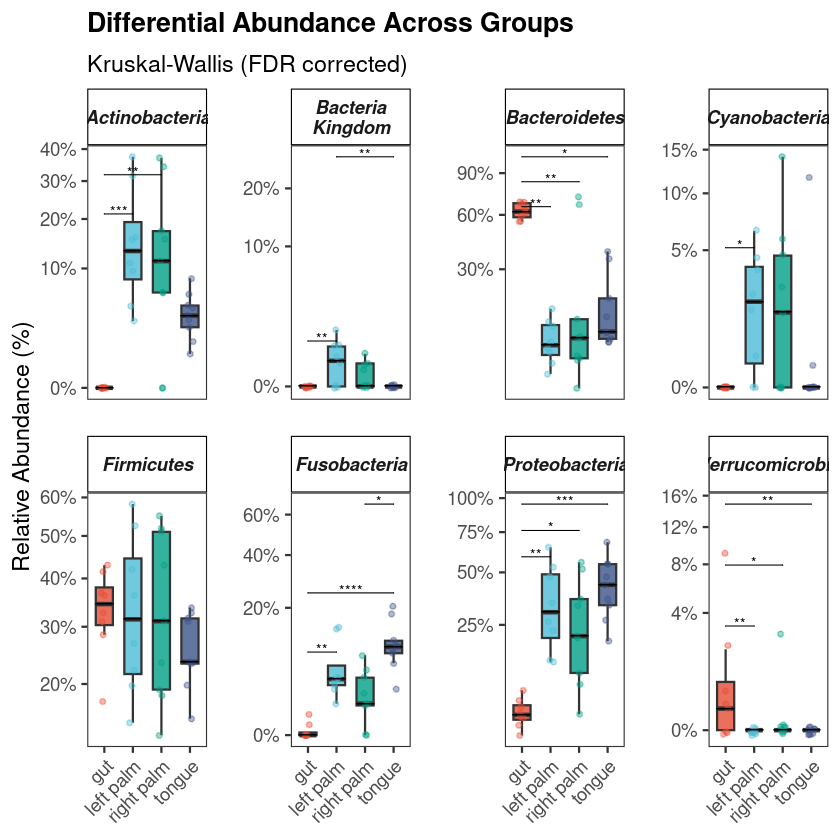
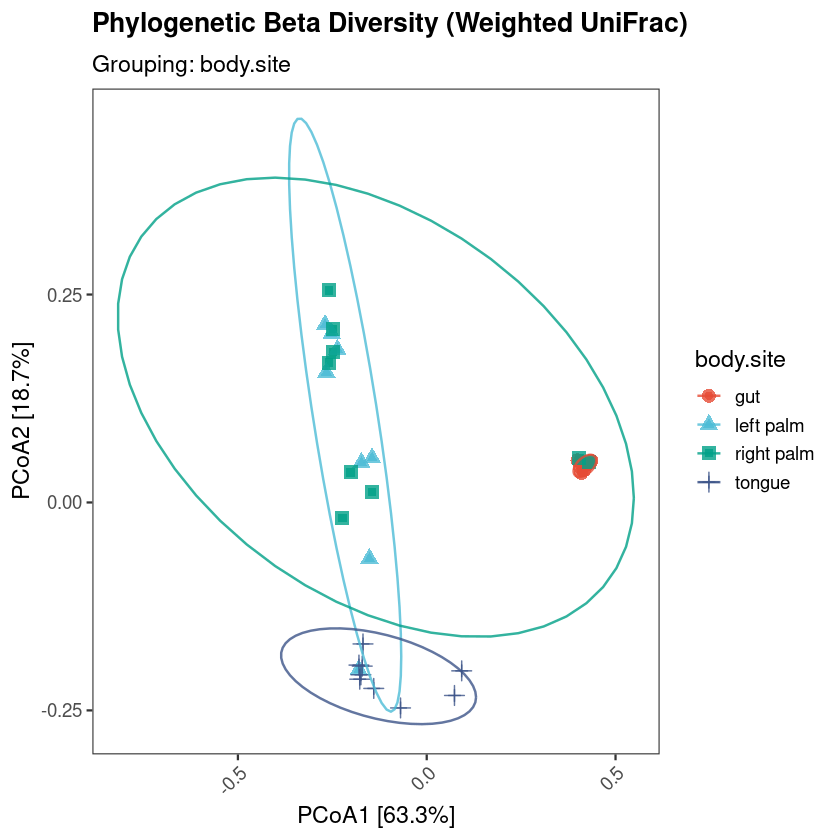
Get a ready-to-use 16S R code workflow and complete 16S pipeline for NGS meta-barcoding data downstream analysis and visualization in R. The script generates analysis-ready figures, exported CSV files, and a Methods section for microbiome projects.
Instant download. Individual license. No subscription.
Analysis frameworkfully commented R code
13analysis sections
33+figures produced
5CSV exports
QZA + CSVboth formats